On instances, primitives, and the difference between novelty that compounds and novelty that merely accumulates.
“The limits of my language mean the limits of my world.” – Wittgenstein, Tractatus 5.6
At first it looked like progress.
For one week, an AI Agent pipeline kept shipping. Commits arrived roughly every hour. Small fixes landed, minor improvements accumulated, the activity graph looked alive. Only one thing was missing: the product itself did not become larger 1. It was not broken. It was not idle. It was moving, but inside a vocabulary it already had.
That confusion is not rare. Conway’s Game of Life has produced new patterns for half a century, and when its central open question about oscillators was settled in 2023, the community did not wind down; it accelerated. Speedrunning communities deliberately ban whole classes of glitches and still find new routes inside the smaller rule book. Out-of-print fighting games keep tournaments alive on rule sets that have been frozen for decades. Most viral internet ideas, by contrast, are mined out within a month and quietly abandoned.
From the outside, all of these can look like activity. The easy diagnosis is “the well is dry,” but that is often too crude. The Game of Life community could be plateauing; the agent pipeline could still be growing; the viral fad might still have another form waiting somewhere. The thing that separates these cases is not visible in the usual busyness metrics, but it is sharp enough to name, and in principle sharp enough to measure.
So the question is: what is the difference between a system that is producing and a system that is growing? Between motion and progress? “Vibe” is not a metric. The distinction needs a name.
The uncomfortable part is that the distinction is not subtle. After the next two sections almost everyone will say “yes, of course.” And yet most of the systems we actually run, build, and reward are the ones that erase the difference. The point of this essay is less the distinction itself than the structural reason we keep walking into it.
More Is Not New
The distinction is simple: there are two kinds of novelty, and we routinely confuse them.
The first is instance novelty: a previously unseen output. A new solution, a new feature, a new generated artifact. The second is primitive novelty: a new reusable building block, something that enters the vocabulary and changes what becomes cheap to say or do next.
A finite grammar can generate infinitely many sentences. That fact is the trap. A system can produce an unbounded stream of genuinely new instances without adding a single new primitive. From the outside it looks open-ended. Underneath, the vocabulary has stopped moving. There is always something new to say, and nothing new to say it with.
Once the distinction is visible, examples are everywhere. A pop-song generator can produce ten thousand chord progressions without introducing a new chord. A research subfield can publish for a decade, every paper different, while quietly running on the same three theorems it started with. An organization can ship features for years on an architecture nobody is allowed to question. A solo creative practice can jump between one-off experiments where each piece is new and none of them make the next one easier. The outputs are genuinely novel. The vocabulary is frozen. The system is productive, but it is not becoming more generative.
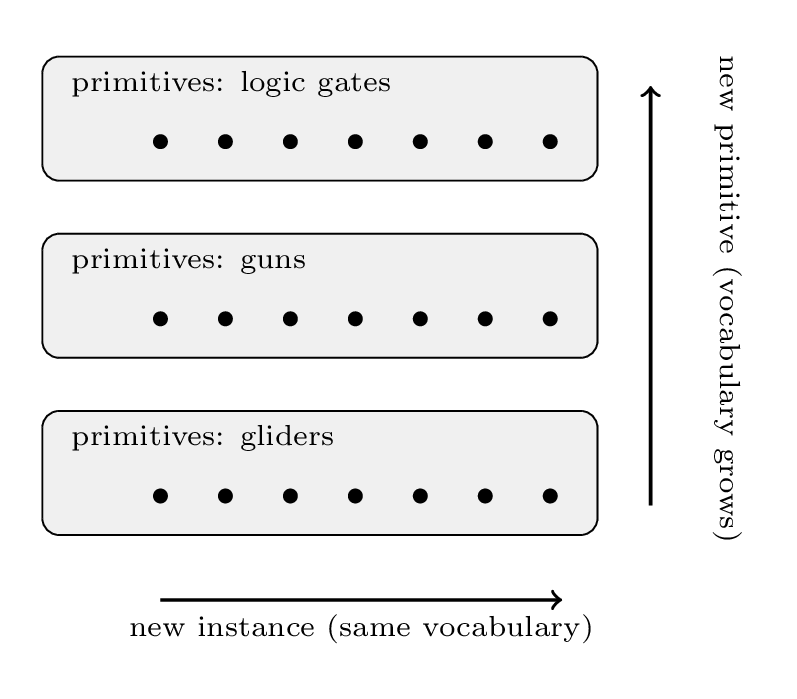 Fig 1: Instance novelty vs primitive novelty. Filling a level with more instances (horizontal) is not the same as promoting a new reusable primitive that opens a level (vertical). A finite grammar yields unboundedly many instances at fixed primitive height.
Fig 1: Instance novelty vs primitive novelty. Filling a level with more instances (horizontal) is not the same as promoting a new reusable primitive that opens a level (vertical). A finite grammar yields unboundedly many instances at fixed primitive height.
The cellular automata world gives the cleanest example, and it is a real result, not just a metaphor. In 2023 it was proven that Conway’s Game of Life has an oscillator of every period; the system is “omniperiodic” 2. That closed an entire family of instance questions at once: is there a thing that blinks with period N? Yes, for all N.
A community might be expected to slow down after a central open problem is solved. The opposite happened. The constructions invented along the way, the reusable techniques for engineering behavior into the grid, were primitives, and the community immediately carried them into new questions. The oscillators were instances. The ways of building them were primitives. They move on different clocks, and mixing them up is one way to misread whether a field, a community, or any system is still alive.
The Two Curves
One picture is enough for the rest of the argument. Run any open-ended system over time and track two numbers.
$g_{\text{inst}}$ (instance yield): how surprising each new output is, given everything that came before. How much genuinely new stuff is arriving.
$g_{\text{prim}}$ (primitive yield): how often a genuinely new reusable building block gets promoted into the vocabulary.
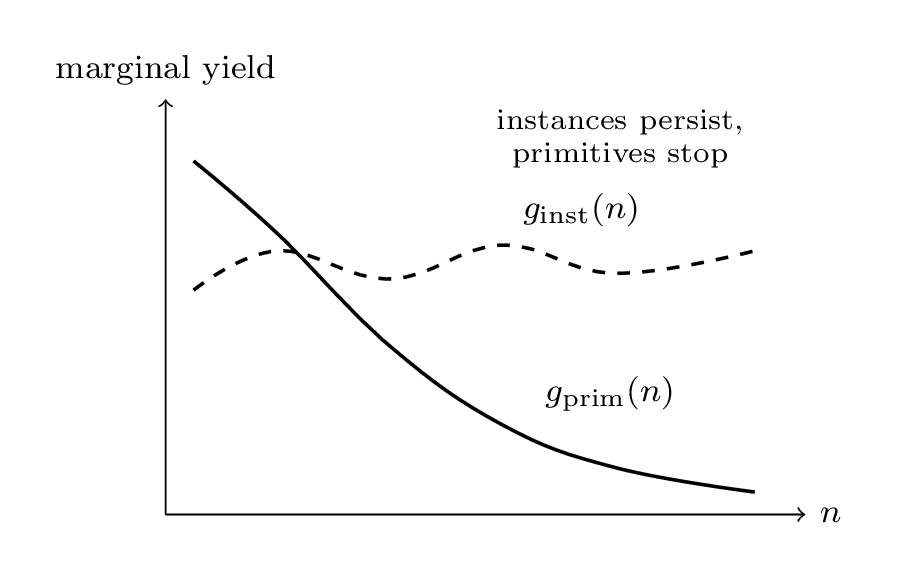 Fig 2: The two-curve criterion. Instance-level marginal complexity $g{\text{inst}}$ stays bounded away from zero while primitive-level marginal yield $g_{\text{prim}}$ decays to zero: unboundedly many novel instances, yet generative closure._
Fig 2: The two-curve criterion. Instance-level marginal complexity $g{\text{inst}}$ stays bounded away from zero while primitive-level marginal yield $g_{\text{prim}}$ decays to zero: unboundedly many novel instances, yet generative closure._
The diagnostic is not the level of either curve. It is their divergence. The failure mode that looks healthy from a distance goes like this: $g_{\text{inst}}$ stays high, new instances keep coming, while $g_{\text{prim}}$ quietly decays toward zero. There are no new building blocks. Infinitely many instances, generative closure. The busyness metrics can stay green exactly when the thing that matters has flattened.
The same shape appears at very different scales. A research group that keeps publishing variations of the same trick has high $g_{\text{inst}}$ and near-zero $g_{\text{prim}}$: every paper is new, but the toolkit is frozen. A craft practice that moves from one-off experiment to one-off experiment has the same signature: a new piece each week, none of them inheriting much from the last. A late paradigm in science can look similar: work continues, anomalies are absorbed, but no new explanatory primitives enter the canon. In each case, the first useful move is to ask where new primitives could actually form, instead of spending all attention on more instances of the old ones.
So the first practical move is almost embarrassingly simple: stop watching one curve. Output volume and instance novelty are vanity metrics. They can look great during a plateau. The number to watch is primitive yield, and it behaves very differently.
What Counts as a New Primitive
“Reusable building block” is still vague. Here a useful idea from program synthesis does real work, and it is the only formula in this essay worth remembering.
A candidate counts as a primitive only when adding it to the library makes the total description of past work shorter. Write the sum of two costs:
$$\text{cost}(\text{library}) ;+; \text{cost}(\text{work, expressed in terms of the library})$$
Adding an abstraction costs something: the library grows. It pays only if everything written using it gets cheaper. The hard part of this test is that it is retrospective. A new “abstraction” cannot be qualified by looking at its design, or by how clean it feels in code review. It has to be applied to old work, and the description has to get shorter. If past work does not compress, future work probably will not either. That is the operational form of the distinction the rest of this essay is built on.
This is what library-learning systems like DreamCoder 3 and Stitch 4 do: they comb through a corpus of solutions and promote the abstractions that maximize compression. The useful point is that this is not mystical and it is not a vibe. A reusable skill is one that allows past work to be re-described more compactly, because it factors out a pattern that kept being re-derived. That gives an operational test for whether a system is accumulating capability or only accumulating output: is its library compressing its own history, or not?
This also reframes what a good open-ended structure is for, whether that structure is a research group, an artistic movement, a software organization, or an autonomous system. For generativity 5, task completion is not enough. The system needs a persistent, shared library and an incentive to compress into it: a structural reason for someone, or something, to notice that the same pattern has appeared five times and should become a primitive. Without that, every cycle starts from the same vocabulary, and the primitive curve never lifts off 6.
Why We Keep Forgetting This
So far this is mostly a definition, and an obvious one. Most systems run by experienced people are run by people who already know, in some form, that mere output is not capability. So why does the same pattern keep reappearing, in shipped product after shipped product, agent system after agent system, lab after lab?
The answer is structural. Every running system has an accounting layer: a changelog, a velocity dashboard, an OKR sheet, an evaluation harness, a paper count. Those layers track output. None of them track library compression. The changelog records what the system did; the library records what it became. The two are not on the same dashboard, because the second one is hard to define and harder to incentivize, and people optimize what they can see paid out.
In practice that means the things that get rewarded are the things that get measured. A pull request closes a ticket and the closing is visible. An engineer who instead spends a week retiring three modules and adding one cleaner primitive does roughly the same amount of work and produces nothing the system can score as “shipped.” Across enough quarters, the incentive ratchet eats the library. The system trends, predictably, toward higher $g_{\text{inst}}$ and lower $g_{\text{prim}}$.
Consider two systems. The first ships a feature every day; its dashboard glows green; its team is celebrated. The second ships nothing for a month while a team rebuilds an internal representation nobody outside the org will ever see. Most accounting layers cannot tell you that, six months on, the second is producing twice as many primitives per quarter as the first, and the first is on a curve toward exhaustion. The honest reading reverses the obvious one.
The same shape recurs in less commercial settings. Research labs that count publications converge on instance work. AI agent benchmarks that score pass rates select for agents that solve more problems with the same vocabulary, not for agents that grow a vocabulary at all. Generative-AI products priced by tokens are economically indifferent to whether the next token came from a compressed concept or a re-derivation. In each case the accounting layer cannot see the variable that actually matters, so the system optimizes a proxy.
So the embarrassing fact is not that “more is not new” is a sophisticated insight some organization might fail to grasp. The fact is that the insight is obvious, almost everyone running these systems will agree with it on a whiteboard, and the systems still produce the wrong answer because nobody has written the right one down in a place that pays out money.
The Second Trap: Lock-In
Suppose the primitives are available. The current way of framing the problem is exhausted, but a better frame exists: a new representation, a new theoretical kit, a new architecture, something that would reopen the primitive curve. Does the system move to it?
Usually not. This is a different failure from “nothing left to find.” It is lock-in: the system should move and cannot. Kuhn’s account of scientific revolutions is largely a study of this 7: anomalies accumulate, the community keeps not switching, and eventually the cost of staying exceeds the cost of jumping. The field then reorganizes in a discrete jump rather than a smooth transition.
The math here is only a comparison. A system switches frames when the gain from switching, call it $\Delta g$, exceeds the cost of switching, $c$. It stays locked in whenever $c > \Delta g$. Two flavors matter:
Pure convention. The alternatives are about equally good. A system is stuck on one for historical reasons, and the cost of changing is not worth it. QWERTY is the classic case 8. Often harmless.
Coordination lock-in. The new frame is genuinely better ($\Delta g > 0$), but the cost of everyone relearning the shared vocabulary, rebuilding the tooling, and recoordinating evaluation standards exceeds the gain. This is the expensive one. It is the shape of pre-Copernican astronomy carrying epicycles on epicycles for centuries, each patch a competent local fix, the underlying frame left unquestioned. It is also the shape of mature engineering organizations whose process makes the leap unrepresentable, so that “pause delivery for three weeks and rethink the topology” is not a sentence the structure can accept 9. The frame will not question itself.
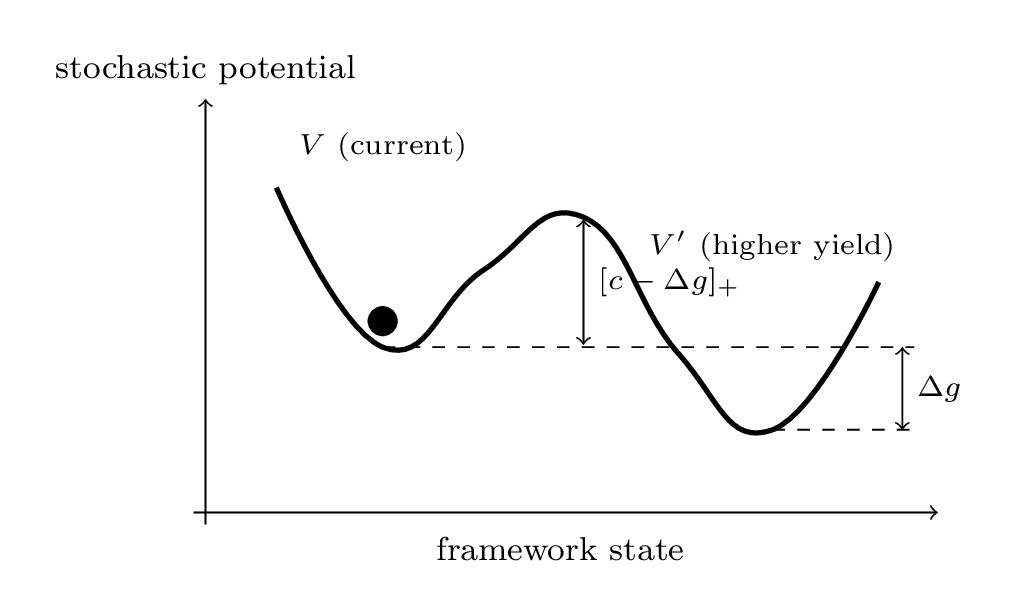 Fig 3: Lock-in as a potential landscape. Even when a better framework $V'$ exists ($\Delta g > 0$), the collective stays in $V$ if the escape resistance $[c - \Delta g]+$ exceeds the available perturbations: a metastable basin. Pure-convention lock-in is the special case $\Delta g \approx 0$._
Fig 3: Lock-in as a potential landscape. Even when a better framework $V'$ exists ($\Delta g > 0$), the collective stays in $V$ if the escape resistance $[c - \Delta g]+$ exceeds the available perturbations: a metastable basin. Pure-convention lock-in is the special case $\Delta g \approx 0$._
Put the two traps on perpendicular axes and a richer picture appears.
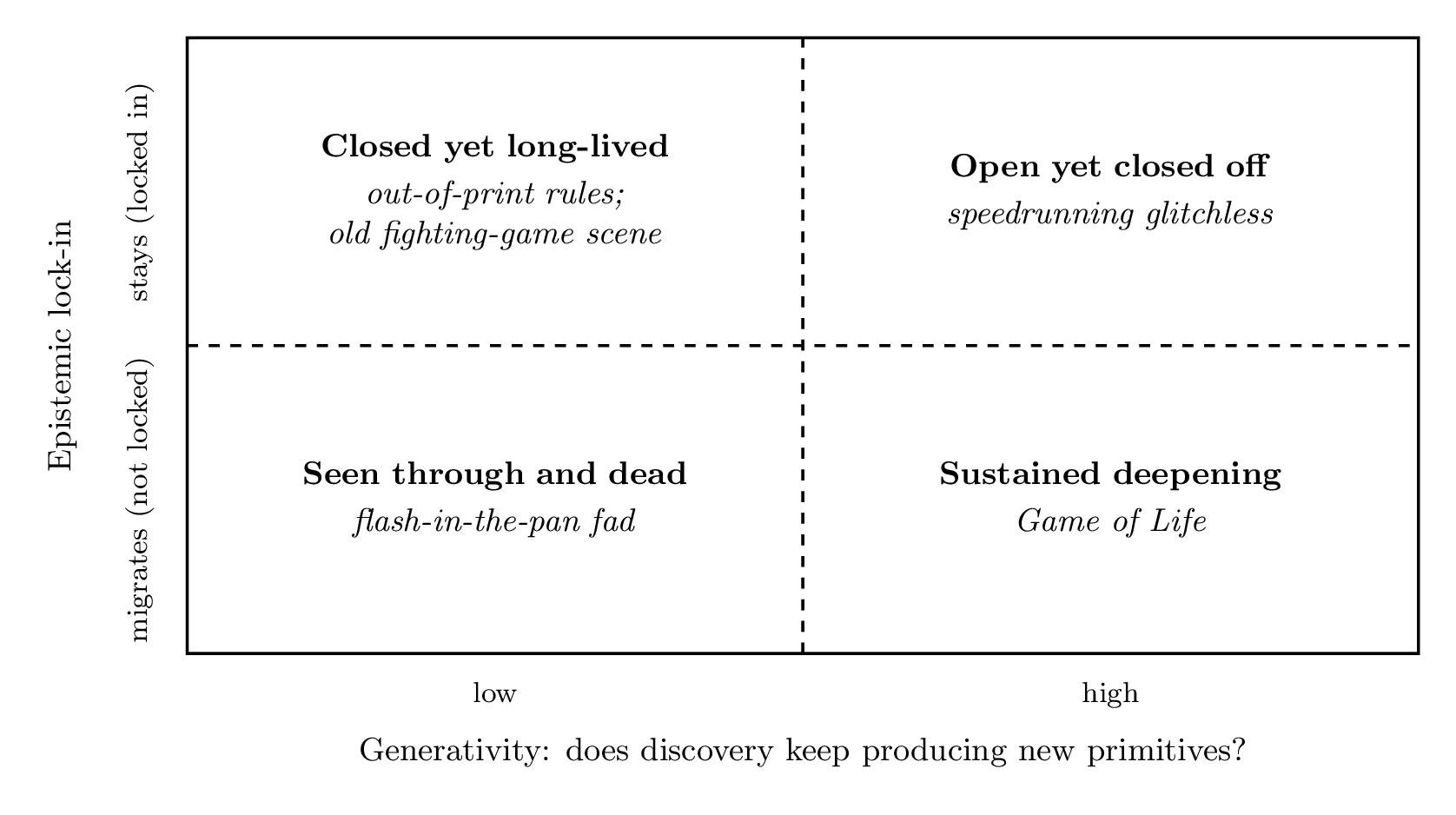 Fig 4: Two axes generate four corners. Generativity (does discovery keep producing new primitives?) is the horizontal axis. Epistemic lock-in (when yield decays, does the collective stay?) is the vertical. Low-generativity, low-lock-in is the flash-in-the-pan fad: once people see through it, they leave. Low-generativity, high-lock-in is the long-lived culture on closed rules: an out-of-print game with a competitive scene that lasts decades. High-generativity, low-lock-in is the open community deliberately bounding itself: speedrunning a still-rich game under “glitchless” rules. High-generativity, high-lock-in is sustained deepening: Game of Life fifty years on.
Fig 4: Two axes generate four corners. Generativity (does discovery keep producing new primitives?) is the horizontal axis. Epistemic lock-in (when yield decays, does the collective stay?) is the vertical. Low-generativity, low-lock-in is the flash-in-the-pan fad: once people see through it, they leave. Low-generativity, high-lock-in is the long-lived culture on closed rules: an out-of-print game with a competitive scene that lasts decades. High-generativity, low-lock-in is the open community deliberately bounding itself: speedrunning a still-rich game under “glitchless” rules. High-generativity, high-lock-in is sustained deepening: Game of Life fifty years on.
Most writing about “open-endedness” sees only one axis at a time. For a stalled system it helps to ask both before reaching for an answer. Even a genuinely generative system will plateau if it is welded to a representation whose primitive curve has flattened, and no amount of local cleverness gets it out. Migration is a different operation from optimization. It has a real cost, and someone, usually still a human, has to decide to pay it on purpose.
One sharper thing to say about both traps. What can actually be measured is never a system’s raw capacity for primitive generation; the measurable quantity is how many primitives were actualized, given where attention was spent. Two systems with access to the same material can trace wildly different libraries depending on how attention is allocated 10. Lock-in is the special case where attention is pointed at a flat curve and the structure will not let it move.
The Hard Part Is Not the Idea
The argument has a definition, a test, an explanation for why systems keep failing the test, and a separate trap that catches the ones that pass it. None of the pieces is hard. The hard part, the part that actually matters, is the second one: knowing the distinction does not get a system out of the trap, because the trap is in the accounting layer, not in anyone’s understanding.
So the working version of the test is short. A system’s real state is not in its output sequence. It is in its library. The changelog says what it did; the library says what it became. Most measurement systems only count the first. A few systems somehow find a way to also count the second. The rest stay busy.
关于两种"新":一种会复利,一种只是越堆越多。
我语言的边界,就是我世界的边界。 – 维特根斯坦《逻辑哲学论》5.6
最初那一周,看起来一切都还挺正常。
我跑的那条 AI Agent 流水线几乎每小时提交一次 commit,活动图绿得发亮,从外面看完全是一个健康的系统该有的样子。问题只有一个:产品本身并没有变大1。它没有崩,也没有停下,commit 一直在落,但所有动作都发生在它已经掌握的那点词汇之内。
这种错觉其实并不少见。Conway’s Game of Life 持续产出新图样已经有半个世纪了,2023 年它关于振子的那个核心未解问题刚被解决,社区不仅没有冷下来,反而加了速。speedrunning 的圈子主动把整类 glitch 排除在比赛规则之外,可即便如此,依然能在剩下的更小的规则框架里挖出新的路线。一些早已绝版的格斗游戏,规则冻结了二十年,比赛照办不误。与此同时,互联网上绝大多数所谓"爆款",往往一个月之内就被掏空,然后被悄无声息地放下。
从外面看,这几种情况其实都叫做"活跃"。最顺嘴的解释一般是"井干了",但这句话往往太粗:Game of Life 也可能只是在触顶,那条 Agent 流水线也可能还在生长,“爆款"也未必死,它可能只是换了一种形态。真正把这几种情况分开的那个东西,并不在忙碌指标里;但它也不仅仅是一种"感觉”,它可以被指认出来,原则上也能被测出来。
所以问题落到一句话上:一个在产出的系统,和一个在成长的系统,到底差在哪里? “运动"和"进步"之间相差的那一截,究竟是什么?“感觉"显然不算指标。这个差别值得被起一个名字。
让人不太舒服的地方在于,这个区分本身一点都不微妙。下面两节看完,绝大多数人都会说一句"这不显然吗”。然而我们真正在跑的系统、在建的组织、在奖励的工作,恰恰是把这个差别一并抹掉的那些。换句话说,这篇文章想讲的其实并不是这个区分本身,而是为什么我们明明知道,却还是会一次又一次地走进去。
多不等于新
要把话讲清楚,得先把两种"新"分开。
第一种是实例层面的新(instance novelty):又一个之前没出现过的输出。新的解法、新的功能、新的产物,都属于这一类。第二种是原语层面的新(primitive novelty):一块新的可复用积木,它进入词汇表之后,会改变"下一次能轻松说出什么"的边界。
陷阱出在这两种"新"看起来太像同一种。有限的语法可以生成无穷多句子;同样,一个系统也可以源源不断地产出真正新颖的实例,而一个新原语都没添过。表面上看,它是开放的、无界的;骨子里,词汇早就停了。永远有新的话可以说,却没有新的东西用来说。
把这个区分摆出来之后,例子就一个接一个地浮上来。一个流行歌曲生成器可以产出一万种和弦走向,而新和弦的数量是零。一个研究子领域可以连发十年的论文,每一篇都不重样,但它一直只是在最初那三个定理上打转。一家公司可以在一个谁都不敢动的架构上连续交付几年的新功能。一个人的创作实践,也可以在一次性的实验之间反复横跳,每件作品都是新的,却没有任何一件让下一件做起来更省力。输出确实是新的,词汇却没动过。这样的系统在产出,但它并没有因此变得更会生成。
图 1:实例层面的新与原语层面的新。在同一层上多塞几个实例(横向),并不等于提升出一块能开下一层的可复用原语(纵向)。一个有限的语法,可以在固定的原语高度上产出无穷多实例。
元胞自动机的世界给出了最干净的例子,而且这不是一个隐喻,是一个真结果。2023 年,有人证明了 Conway’s Game of Life 拥有任意周期的振子,整个系统是"全周期的”(omniperiodic)2。这一下,一整族实例层面的问题就此关上了门:是否存在以周期 N 闪烁的图样? 存在,对所有 N 都存在。
按常理说,刚把一个核心未解问题解掉的社区应该平息下来,但事实恰恰相反。原因其实并不复杂:解题过程中发明出来的那些构造方法(也就是把行为工程化进网格的可复用技术)本身就是一批原语。问题一关门,社区立刻就把这些方法带去了新的问题上。换句话说,振子是实例,造振子的方法是原语,二者跑在完全不同的两个时钟上。把它们混作一谈,恰恰就是误判一个领域、一个社区,或者任何一个系统是否还活着的根源。
两条曲线
只需要一张图就够:让一个开放性系统跑得足够久,然后盯两个数字。
$g_{\text{inst}}$(实例产率):在已知的一切之外,每个新输出有多出人意料;说穿了,就是真正新的东西到达的速度。
$g_{\text{prim}}$(原语产率):真正新的、可复用的积木被提升进词汇表的频率。
图 2:两条曲线的判据。实例层的边际复杂度 $g{\text{inst}}$ 长期高于零,原语层的边际产率 $g_{\text{prim}}$ 却已经衰减到零:实例无穷无尽,生成性那边却已经关门。_
真正要看的并不是某一条曲线的高度,而是两条曲线之间的背离。最容易骗人的那种失败模式长这样:$g_{\text{inst}}$ 一直很高,新实例源源不断地涌出;$g_{\text{prim}}$ 却悄悄地掉到了零,没有新积木出现了。实例可以无穷无尽,生成性那一边却已经关门。所有"忙碌"指标恰恰就是在这种时候依然是绿的,而真正要紧的那条曲线已经躺平。
同样的形状,会在很不同的尺度上反复出现。一个只在同一个套路上做变体的研究小组,看起来就是 $g_{\text{inst}}$ 很高、$g_{\text{prim}}$ 接近零:每篇论文都是新的,工具箱却从未变过。一个反复做一次性实验的创作者,也是同样的指纹:每周一件新作品,但没有任何一件接得上上一件。任何一门学科进入晚期范式的时候,也带着相似的印记:工作仍在继续,反例被一一吸收,但没有新的解释性原语进入正典。每一种情况下,第一个真正有用的问题其实都是同一个:新原语可能从哪里冒出来?而不是在旧原语身上再多堆几个新实例。
由此得出的第一步实践,简单到有点尴尬:不要只盯一条曲线。 输出量和实例新度是虚荣指标,触顶的时候它们依然漂亮。真正该盯的,是原语产率,而它的行为完全是另一回事。
什么算一块新原语
“可复用积木"还是太空。要把话钉实,需要一个来自程序合成(program synthesis)的判据,它也是本文里唯一值得记住的那个公式。
一个候选积木算不算原语,归根结底只看一件事:把它加进库以后,过去工作的总描述长度有没有变短。 把两份代价加在一起:
$$\text{cost}(\text{library}) ;+; \text{cost}(\text{work, expressed in terms of the library})$$
加一个抽象是要付钱的,因为库会变大。它要划算,就得让其他一切都跟着变便宜。这个判据真正难的地方在于:它是回溯性的。一个新"抽象"成不成立,不能光看它的设计是否漂亮,也不能光看它在 code review 里读起来有多干净,必须把它套回到过去的工作上,看描述长度有没有掉下来。换句话说,压不动过去,多半也打不开未来。 这就是这篇文章后面所有论证依赖的那个区分的可操作版本。
DreamCoder 3 和 Stitch 4 这类库学习系统做的正是这件事:把一份解法语料梳一遍,把最能压缩历史的抽象提升进库。所谓可复用的技能,归根结底就是能让过去的工作被更紧凑地重新描述的那种技能,因为它把一个反复推导过的模式整个抽了出去。它既不玄,也不靠感觉。 这就给了一个可操作的入口,用来判断一个系统到底是在积累能力,还是只在积累输出:它的库有没有在压缩它自己的历史?
由此还可以反过来重新界定一个好的开放性结构究竟是为了什么,不论那个结构是一个研究小组、一场艺术运动、一家软件公司,还是一个自主系统。如果要的是生成性5,光把任务做完是远远不够的:系统得有一个持久的、共享的库,得有一个把东西压缩进去的激励;同一种问题形状第五次出现的时候,应当有人、或者某个机制,把它提升成原语。否则每一轮都是从同一份词汇开始,原语曲线永远起不来 6。
为什么我们一再忘记这件事
到这里为止,定义本身其实是明摆着的。在跑系统、做组织、写论文这些事情上有点经验的人,多多少少都明白"产出不等于能力”。可问题恰恰在这里:既然这么明白,那同一种模式为什么还是会在一个又一个产品里、一个又一个 Agent 系统里、一个又一个实验室里反复上演?
原因不在认知层,而在结构层。任何一个真正在运转的系统都会带着一个会计层:changelog、velocity 看板、OKR 表、评估管道、论文数。这些东西数的全部是产出,没有一项在数库的压缩。changelog 记的是这个系统做了什么;library 记的是它变成了什么。 这两件事永远不会出现在同一张表上,因为后者难定义、更难奖励,而人本能上就会去优化看得见、能换出工资的那一项。
具体到日常:奖励的东西,是测量的东西。一个 pull request 关掉一个 ticket,整个动作清清楚楚摆在那里。换一个工程师,花一整周把三个模块合并成一个更干净的原语,活做了,可没有任何一项"已交付"指标会把这件事记下来。几个季度走下来,激励的棘轮会把库一点一点吃干净,系统的轨迹就这样不动声色地朝高 $g_{\text{inst}}$、低 $g_{\text{prim}}$ 的方向滑过去。
不妨设想两个并存的系统。一个每天都有新功能交付,仪表盘绿得发亮,团队一次又一次被表扬;另一个一整个月对外什么都不交付,所有人在重构一个外部用户永远看不到的内部表示。半年之后,第二个系统每季度长出来的原语其实是第一个的两倍,而第一个早已在走向枯竭。可这件事,绝大多数会计层根本看不出来。
非商业的场景,长出的也是同一个形状。以发表数为指标的实验室,会一步一步地走向实例工作;以通过率为指标的 AI Agent benchmark,挑出来的是"用同一套词汇解出更多题"的 Agent,而不是会去长出一套新词汇的 Agent;按 token 计价的生成式 AI 产品,经济上根本分不清一个 token 是从一个已经压缩过的概念里出来的,还是又一次被重新推导出来的。每一种场景里,会计层都恰好屏蔽掉了那个真正要紧的变量,于是系统就一路把代理指标优化下去。
所以真正难堪的地方,不是"多不等于新"是一个什么深奥洞察、某些组织没能领会到。难堪的是:这件事再明白不过,所有在跑系统的人在白板前都会点头同意,可系统照样在产出错误答案。原因其实只有一个:没有人把正确答案写在那个能换出工资的位置上。
第二个陷阱:锁定
退一步说,假设原语确实存在。当下框定问题的方式已经被掏空了,但旁边其实就有另一个更好的框架:一种新的表示,一套新的理论工具,一个新的架构,足以把原语曲线重新打开。系统会迁过去吗?
通常不会。这种失败和"已经没东西可找"是两回事,它叫锁定(lock-in):系统该动,却动不了。库恩对"科学革命"的整套描述,本质上就是在研究这件事7:反例一再积累,社区却始终不切换,直到留在原地的成本最终压过了跳出去的成本,整个领域不是一点一点过渡过来的,而是以一次跳跃把自己重新组织一遍。
底下的数学其实只是个比较:切换带来的增益 $\Delta g$ 超过切换成本 $c$ 时,系统才会切;$c > \Delta g$ 时,系统就锁死。锁定一般分两种:
纯粹的惯例(Pure convention)。 几个备选项大致一样好,只是历史原因卡在了其中一个上,换的成本不值得付。QWERTY 是经典的例子8。多数情况下无害。
协调性锁定(Coordination lock-in)。 新框架真的更好($\Delta g > 0$),但所有人重新学共享词汇、重建工具链、重新协调评估标准的成本加起来,已经超过了那点增益。昂贵的就是这一种。哥白尼之前的天文学就是这副样子,几百年里本轮叠本轮:每一个补丁本身都是合格的局部修正,但底层框架始终没被人质疑过。成熟工程组织里的多数流程,性质也差不多:结构本身让"暂停交付三周,重新想一下拓扑"这种话根本无法被说出口9。框架不会自己质疑自己。
图 3:锁定,作为一个势能景观。即便存在一个更好的框架 $V'$($\Delta g > 0$),只要逃逸阻力 $[c - \Delta g]+$ 超过了可用的扰动,集体就会停留在 $V$ 这个亚稳态的洼地里。纯惯例锁定不过是 $\Delta g \approx 0$ 这一特例。_
把这两个陷阱放到一对正交的轴上,更完整的图就出来了。
图 4:两条轴生出四个角落。生成性(探索是否还在持续产出新的原语?)是横轴;认知锁定(在产率衰减之后,集体会不会停下来?)是纵轴。低生成性、低锁定,是流星式的"爆款":一旦被看穿,人就走。低生成性、高锁定,是在已封闭规则上长期延续的文化:一款绝版游戏却拥有持续了几十年的竞技场。高生成性、低锁定,是一个开放的社区主动给自己设界,比如在仍然内容丰富的游戏中以"无 glitch"规则速通。高生成性、高锁定,是 Game of Life 五十年来始终所在的那一格:“持续深入”。
关于"开放性"的讨论,多数时候只看其中一条轴。但凡碰到一个触顶的系统,最稳妥的做法是把两条轴都问一遍,再急着下结论。哪怕一个有生成性的系统,被焊死在一个原语曲线已经走平的表示上,照样会触顶,再多的局部聪明也救不回来。迁移和优化是两件性质不同的事;迁移要付真金白银的代价,而且这笔代价通常还得有人主动决定承不承担。
关于这两个陷阱,最后再补一句更锋利的:真正能被测出来的,从来不是系统生成原语的原始能力,而是在注意力实际落到的那条路径上,到底有多少原语被实现了。两个接触同样底层材料的系统,会因为注意力分配方式不同而长出截然不同的库10。锁定不过是这个机制的一种特殊形态:注意力被指到了一条已经走平的曲线上,而结构不肯让它再动。
难的不是这个想法
到这里,能讲清楚的差不多都讲了:什么是原语,怎么测它,为什么系统再三测不出来,以及就算测出来又会被另一个陷阱接住。每一件单看都不复杂。可真正棘手的是另外一件事:明白这个区分,并不能把系统救出来。陷阱根本不在认知层,它躲在会计层里。
落到工作上,这个判据其实可以非常短。一个系统真正的状态,不在它的输出序列里,而在它的库里。changelog 记的是它做了什么,library 记的是它变成了什么。绝大多数测量系统只数前者;少数能成长的系统,不知怎么的,找到了同时去数后者的办法。其余的,只是在忙。
References
-
Changkun Ou. (2026). AI Agents (or Humans) in Goal-Directed and Goalless Environments. The prior essay this one extends. ↩︎
-
Brown, N., Cheney, C., Eppstein, D., Goucher, A. P., Hartzer, D., Jacobi, M. D., Knight, A. P., Mead, W. P., Niemiec, M. D., Raucci, S., Riley, M. D., Rokicki, T., Santiago, A., & Vagle, M. (2024). Conway’s Game of Life is omniperiodic. arXiv:2312.02799 ↩︎
-
Ellis, K., Wong, C., Nye, M., Sablé-Meyer, M., Morales, L., Hewitt, L., Cary, L., Solar-Lezama, A., & Tenenbaum, J. B. (2023). DreamCoder: growing generalizable, interpretable knowledge with wake–sleep Bayesian program learning. Philosophical Transactions of the Royal Society A, 381(2251). ↩︎
-
Bowers, M., Olausson, T. X., Wong, L., Grand, G., Tenenbaum, J. B., Ellis, K., & Solar-Lezama, A. (2023). Top-down synthesis for library learning. Proc. ACM Program. Lang., 7(POPL). arXiv:2211.16605 ↩︎
-
Hughes, E., Dennis, M. D., Parker-Holder, J., Behbahani, F., Mavalankar, A., Shi, Y., Schaul, T., & Rocktäschel, T. (2024). Open-endedness is essential for artificial superhuman intelligence. ICML. arXiv:2406.04268 ↩︎
-
Hernandez Cano, L., et al. (2026). Prospective compression in human abstraction learning. arXiv:2605.09985. On library learning when the task distribution is non-stationary, the case that matters most for agents. ↩︎
-
Kuhn, T. S. (1962). The Structure of Scientific Revolutions. University of Chicago Press. The original account of frames that stop yielding and the cost of switching them. ↩︎
-
Arthur, W. B. (1989). Competing technologies, increasing returns, and lock-in by historical events. Economic Journal, 99(394), 116–131. ↩︎
-
Changkun Ou. (2026). Wallfacer: Autonomous Engineering Pipeline that Orchestrates AI Agent Teams. github.com/changkun/wallfacer ↩︎
-
March, J. G. (1991). Exploration and exploitation in organizational learning. Organization Science, 2(1), 71–87. ↩︎